Overview
Jobs are useful if you have scripts that you want to run silently in the background or on a different machine. This quick start guide teaches you how to use cjr to run jobs on your local machine.
Job File Isolation
Jobs run in isolation. When a new job starts, cjr creates a copy of all the files and folders in the user’s project directory. The job will then read and modify the copied directory without affecting any of the files in your project directory. This means that you can start a job, then delete or change all the files in your project directory and the job will keep running unaffected.
At any point in the job lifecycle, you can manually sync changes back to your project directory. The following figure illustrates a typical job lifecycle.
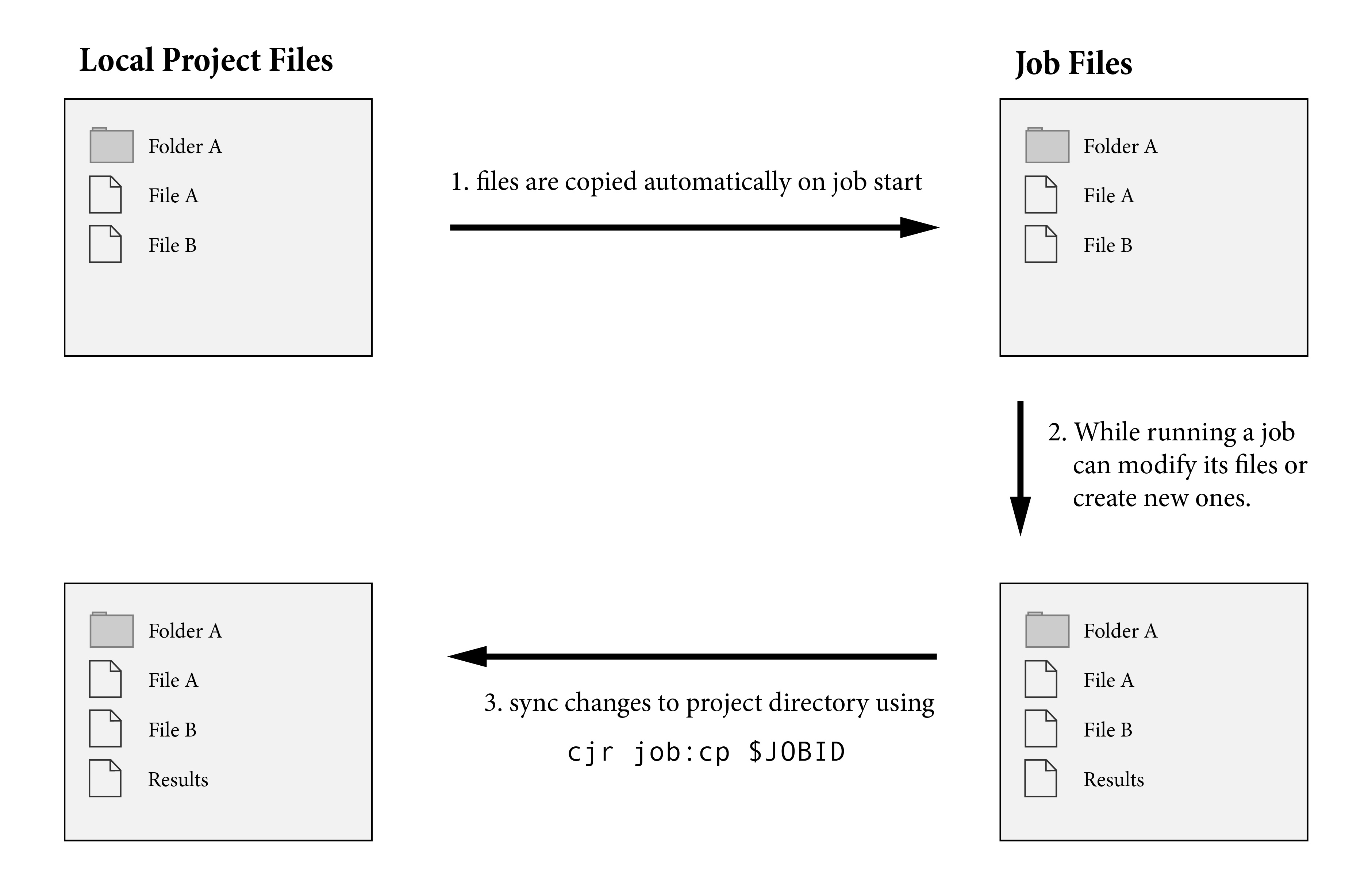
Remark: Jobs run in isolation so that the experience of running jobs on local and remote resources feels identical.
Advanced Users: If you are familiar with Docker, then job files are stored in a separate volume for each job.
Job Types
Jobs can be syncronous (blocking) or asyncronous (nonblocking). When you run a job syncronously you can detach at any time and reattach later; similar to how may use a program like screen or tmux. You can also attach to a running asyncronous job.